为什么 python 不区分全半角
转自本人知乎回答 Python的变量名为什么区分大小写,但不区分全半角?
在使用诸如 print(__name__) 时,print(__name__) 也能得到完全一样的结果。
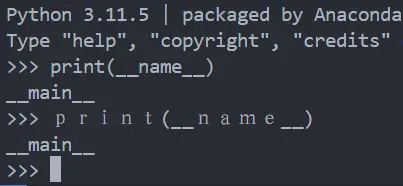
两者结果相同
实际上不只如此,在 https://peps.python.org/pep-0672/#normalizing-identifiers 所举的例子中,英语中的连字 fi(f 和 i 连在一起,是个独立的 Unicode 码)会被 python 视为和普通的两个英文字母 fi 等同;xⁿ 会视为和 xn 等同(也就是 xⁿ = 8,则 print(xn) 也是 8)。
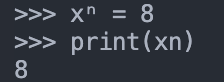
xⁿ 与 xn 等同
为什么呢?这是因为 python 的标识符采用了 Unicode 的 NFKC(Normalization Form Compatibility Composition,兼容等价分解并以标准形态组合)原则进行正规化,解析相关的 Unicode 码,两个正规化后一致的标识符,将视为同一个标识符。
NFKC 是一种将相似的变体 Unicode 字符映射到同一个字符的正规化方案(例如 Å U+212B 和 Å U+00C5 均视为 Å U+00C5) ,与此类似的还有 NFC, NFD, NFKD。具体细节可以查看 wiki:Unicode等价性、官方文档 https://unicode.org/reports/tr15/,以及 从⽅不是方到Unicode正规化NFD, NFC, NFKD, NFKC 和 Unicode等价性与正规化 这两篇博客。
简单来说,NF(K)C、NF(K)D 中 C 和 D 的区别是是否进行组合,例如 が 在 NFC 和 NFKC 正规化后还是 が(先等价化拆分,后组合),在 NFD 和 NFKD 下则是 か 加上浊点 ◌゙(直接等价化拆分)。
而 NFKC、NFKD 相比 NFC、NFD 添加的额外的 K(Compatibility),则是加入了更多的兼容性映射。诸如全角和半角合并(全角的 [n] 视为半角的 [n]),上下标合并(上标 ⁿ 视为普通的 n),连字视为独立字等。但 NFKC/NFKD 并不包含大小写合并(或许是因为“外观”上并不更相似)。
因此,答案是 Python 标识符采用的 NFKC 正规化规则包含了全角和半角的合并,但不包含大小写合并。

NFD, NFC, NFKD, NFKC 对比
NFKC 这种方式更适合搜索引擎,文本中视觉一样的字符,在搜索时也应该被同时查阅。至于 Python 为什么对标识符这么做,我就不得而知了。不过这种正规化在 Python 中仅仅适用于标识符。将字符串视为标识符的函数(例如 getattr)不会执行正规化。
如果你想手动看看这种正规化能进行什么样的映射,可以试试在 Python 中运行下面的语句哦
from unicodedata import normalize
print(normalize('NFKC', "Hello,world!"))
print(normalize('NFD', "안녕하세요"))
参考:
https://peps.python.org/pep-0672/#normalizing-identifiers
wiki:Unicode等价性
https://unicode.org/reports/tr15/
从⽅不是方到Unicode正规化NFD, NFC, NFKD, NFKC
Unicode等价性与正规化